|
[ Chapter start ] [ Previous page ] [ Next page ] 12.2 A Comparator/MUXWith the Verilog behavioral model of Figure 12.1 as the input, logic-synthesis software generates logic that performs the same function as the Verilog. The software then optimizes the logic to produce a structural model, which references logic cells from the cell library and details their connections.
Before running a logic synthesizer, it is necessary to set up paths and startup files (
synopsys_dc.setup
,
compass.boo
,
view.ini
, or similar). These files set the target library and directory locations. Normally it is easier to run logic synthesis in text mode using a script. A
script
is a text file that directs a software tool to execute a series of synthesis commands (we call this a
synthesis run
).
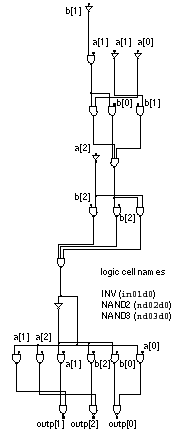
Figure 12.2
shows a structural netlist,
comp_mux_u.v
, and the derived schematic after logic synthesis, but before any
logic
optimization
. A
derived schematic
is created by software from a structural netlist (as opposed to a schematic drawn by hand). Logic synthesis parses (in a process sometimes called analysis ) and translates (sometimes called elaboration ) the input HDL to a data structure. This data structure is then converted to a network of generic logic cells. For example, the network in Figure 12.2 uses NAND gates (each with three or fewer inputs in this case) and inverters. This network of generic logic cells is technology-independent since cell libraries in any technology normally contain NAND gates and inverters. The next step, logic optimization , attempts to improve this technology-independent network under the controls of the designer. The output of the optimization step is an optimized, but still technology-independent, network. Finally, in the logic-mapping step, the synthesizer maps the optimized logic to a specified technology-dependent target cell library. Figure 12.3 shows the results of using a standard-cell library as the target. Text reports such as the one shown in Table 12.3 may be the only output that the designer sees from the logic-synthesis tool. Often, synthesized ASIC netlists and the derived schematics containing thousands of logic cells are far too large to follow. To make things even more difficult, the net names and instance names in synthesized netlists are automatically generated. This makes it hard to see which lines of code in the HDL generated which logic cells in the synthesized netlist or derived schematic.
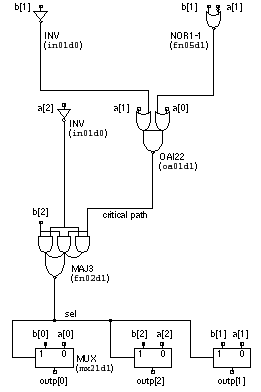
In the comparator/MUX example the derived schematics are simple enough that, with hindsight, it is clear that the XOR logic cell used in the hand design is logically inefficient. Using XOR logic cells does, however, result in the simple schematic of Figure 12.1 . The synthesized version of the comparator/MUX in Figure 12.3 uses complex combinational logic cells that are logically efficient, but the schematic is not as easy to read. Of course, the computer does not care about this—and neither do we since we usually never see the schematic. Which version is best—the hand-designed or the synthesized version? Table 12.3 shows statistics generated by the logic synthesizer for the comparator/MUX. To calculate the performance of each circuit that it evaluates during synthesis, there is a timing-analysis tool (also known as a timing engine ) built into the logic synthesizer. The timing-analysis tool reports that the critical path in the optimized comparator/MUX is 2.43 ns. This critical path is highlighted on the derived schematic of Figure 12.3 and consists of the following delays:
(In this cell library the 'd1' suffix indicates normal drive strength.)
Table 12.4 lists the name, type, the number of transistors, the area, and the delay of each logic cell used in the hand-designed and synthesized comparator/MUX. We could have performed this analysis by hand using the cell-library data book and a calculator or spreadsheet, but it would have been tedious work—especially calculating the delays. The computer is excellent at this type of bookkeeping. We can think of the timing engine of a logic synthesizer as a logic calculator. We see from Table 12.4 that the sum of the widths of all the cells used in the synthesized design (122.4 m m) is less than for the hand design (189.6 m m). All the standard cells in a library are the same height, 72 l or 21.6 m m, in this case. Thus the synthesized design is smaller. We could estimate the critical path of the hand design using the information from the cell-library data book (summarized in Table 12.4 ). Instead we will use the timing engine in the logic synthesizer as a logic calculator to extract the critical path for the hand-designed comparator/MUX. Table 12.5 shows a timing analysis obtained by loading the hand-designed schematic netlist into the logic synthesizer. Table 12.5 shows that the hand-designed (critical path 2.42 ns) and synthesized versions (critical path 2.43 ns) of the comparator/MUX are approximately the same speed. Remember, though, that we used the default settings during logic optimization. Section 12.11 shows that the logic synthesizer can do much better.
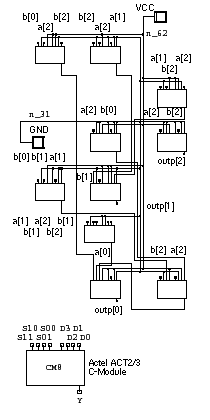
12.2.1 An Actel Version of the Comparator/MUXFigure 12.4 shows the results of targeting the comparator/MUX design to the Actel ACT 2/3 FPGA architecture. (The EDIF converter prefixes all internal nodes in this netlist with 'block_0_DEF_NET_' . This prefix was replaced with 'n_' in the Verilog file, comp_mux_actel_o_adl_e.v , derived from the .adl netlist.) As can be seen by comparing the netlists and schematics in Figures 12.3 and 12.4 , the results are very different between a standard-cell library and the Actel library. Each of the symbols in the schematic in Figure 12.4 represents the eight-input ACT 2/3 C-Module (see Figure 5.4 a). The logic synthesizer, during the technology-mapping step, has decided which connections should be made to the inputs to the combinational logic macro, CM8 . The CM8 names and the ACT2/3 C-Module names (in parentheses) correspond as follows: S00(A0) , S01(B0) , S10(A1) , S11(A2) , D0(D00) , D1(D01) , D2(D10) , D3(D11) , and Y(Y) . 1. Cell Name = cell name from the ASIC library (Compass Passport, 0.6 m m high-density, 5 V standard-cell library, cb60hd230); Num Insts = number of cell instances; Gate Count Per Cell = equivalent gates with two-input NAND = 1 gate (with number of transistors ª equivalent gates ¥ 4); Width Per Cell = width in m m (cell height in this library is 72 l or 21.6 m m); incr = incremental delay time due to logic cell delay; trs = transition; R = rising; F = falling; rampDel = ramp delay; cap = capacitance at node or cell output pin. 3. Average over all inputs with load capacitance equal to two standard loads (one standard load = 0.016 pF). 6. Rise and fall delays are different for the two inputs, A and B, of this cell: t PLHA = 0.48 ns; t PLHB = 0.36 ns; t PHLA = 0.59 ns; t PHLB = 0.33 ns. 7. See footnote 1 in Table 12.3 for explanations of the abbreviations used in this table. [ Chapter start ] [ Previous page ] [ Next page ] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||





 Animation, 3D Art and 3D Models")