|
[ Chapter start ] [ Previous page ] [ Next page ] 14.4 Fault SimulationWe use fault simulation after we have completed logic simulation to see what happens in a design when we deliberately introduce faults. In a production test we only have access to the package pins—the primary inputs ( PIs ) and primary outputs ( POs ). To test an ASIC we must devise a series of sets of input patterns that will detect any faults. A stimulus is the application of one such set of inputs (a test vector ) to the PIs of an ASIC. A typical ASIC may have several hundred PIs and therefore each test vector is several hundred bits long. A test program consists of a set of test vectors. Typical ASIC test programs require tens of thousands and sometimes hundreds of thousands of test vectors. The test-cycle time is the period of time the tester requires to apply the stimulus, sense the POs, and check that the actual output is equal to the expected output. Suppose the test cycle time is 100 ns (corresponding to a test frequency of 10 MHz), in which case we might sense (or strobe ) the POs at 90 ns after the beginning of each test cycle. Using fault simulation we mimic the behavior of the production test. The fault simulator deliberately introduces all possible faults into our ASIC, one at a time, to see if the test program will find them. For the moment we dodge the problem of how to create the thousands of test vectors required in a typical test program and focus on fault simulation. As each fault is inserted, the fault simulator runs our test program. If the fault simulation shows that the POs of the faulty circuit are different than the PIs of the good circuit at any strobe time, then we have a detected fault ; otherwise we have an undetected fault . The list of fault origins is collected in a file and as the faults are inserted and simulated, the results are recorded and the faults are marked according to the result. At the end of fault simulation we can find the fault coverage , Detected faults and detectable faults will be defined in Section 14.4.5 , after the description of fault simulation. For now assume that we wish to achieve close to 100 percent fault coverage. How does fault coverage relate to the ASIC defect level? Table 14.7 shows the results of a typical experiment to measure the relationship between single stuck-at fault coverage and AQL. Table 14.7 completes a circle with test and repair costs in Table 14.1 and defect levels in Table 14.2 . These experimental results are the only justification (but a good one) for our assumptions in adopting the SSF model. We are not quite sure why this model works so well, but, being engineers, as long as it continues to work we do not worry too much.
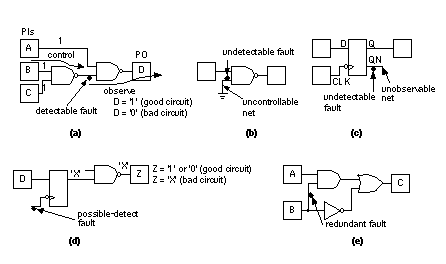
There are several algorithms for fault simulation: serial fault simulation, parallel fault simulation, and concurrent fault simulation. Next, we shall discuss each of these types of fault simulation in turn. 14.4.1 Serial Fault SimulationSerial fault simulation is the simplest fault-simulation algorithm. We simulate two copies of the circuit, the first copy is a good circuit. We then pick a fault and insert it into the faulty circuit. In test terminology, the circuits are called machines , so the two copies are a good machine and a faulty machine . We shall continue to use the term circuit here to show the similarity between logic and fault simulation (the simulators are often the same program used in different modes). We then repeat the process, simulating one faulty circuit at a time. Serial simulation is slow and is impractical for large ASICs. 14.4.2 Parallel Fault SimulationParallel fault simulation takes advantage of multiple bits of the words in computer memory. In the simplest case we need only one bit to represent either a '1' or '0' for each node in the circuit. In a computer that uses a 32-bit word memory we can simulate a set of 32 copies of the circuit at the same time. One copy is the good circuit, and we insert different faults into the other copies. When we need to perform a logic operation, to model an AND gate for example, we can perform the operation across all bits in the word simultaneously. In this case, using one bit per node on a 32-bit machine, we would expect parallel fault simulation to be about 32 times faster than serial simulation. The number of bits per node that we need in order to simulate each circuit depends on the number of states in the logic system we are using. Thus, if we use a four-state system with '1' , '0' , 'X' (unknown), and 'Z' (high-impedance) states, we need two bits per node. Parallel fault simulation is not quite as fast as our simple prediction because we have to simulate all the circuits in parallel until the last fault in the current set is detected. If we use serial simulation we can stop as soon as a fault is detected and then start another fault simulation. Parallel fault simulation is faster than serial fault simulation but not as fast as concurrent fault simulation. It is also difficult to include behavioral models using parallel fault simulation. 14.4.3 Concurrent Fault SimulationConcurrent fault simulation is the most widely used fault-simulation algorithm and takes advantage of the fact that a fault does not affect the whole circuit. Thus we do not need to simulate the whole circuit for each new fault. In concurrent simulation we first completely simulate the good circuit. We then inject a fault and resimulate a copy of only that part of the circuit that behaves differently (this is the diverged circuit ). For example, if the fault is in an inverter that is at a primary output, only the inverter needs to be simulated—we can remove everything preceding the inverter. Keeping track of exactly which parts of the circuit need to be diverged for each new fault is complicated, but the savings in memory and processing that result allow hundreds of faults to be simulated concurrently. Concurrent simulation is split into several chunks, you can usually control how many faults (usually around 100) are simulated in each chunk or pass . Each pass thus consists of a series of test cycles. Every circuit has a unique fault-activity signature that governs the divergence that occurs with different test vectors. Thus every circuit has a different optimum setting for faults per pass . Too few faults per pass will not use resources efficiently. Too many faults per pass will overflow the memory. 14.4.4 Nondeterministic Fault SimulationSerial, parallel, and concurrent fault-simulation algorithms are forms of deterministic fault simulation . In each of these algorithms we use a set of test vectors to simulate a circuit and discover which faults we can detect. If the fault coverage is inadequate, we modify the test vectors and repeat the fault simulation. This is a very time-consuming process. As an alternative we give up trying to simulate every possible fault and instead, using probabilistic fault simulation , we simulate a subset or sample of the faults and extrapolate fault coverage from the sample. In statistical fault simulation we perform a fault-free simulation and use the results to predict fault coverage. This is done by computing measures of observability and controllability at every node. We know that a node is not stuck if we can make the node toggle—that is, change from a '0' to '1' or vice versa. A toggle test checks which nodes toggle as a result of applying test vectors and gives a statistical estimate of vector quality , a measure of faults detected per test vector. There is a strong correlation between high-quality test vectors, the vectors that will detect most faults, and the test vectors that have the highest toggle coverage . Testing for nodes toggling simply requires a single logic simulation that is much faster than complete fault simulation. We can obtain a considerable improvement in fault simulation speed by putting the high-quality test vectors at the beginning of the simulation. The sooner we can detect faults and eliminate them from having to be considered in each simulation, the faster the simulation will progress. We take the same approach when running a production test and initially order the test vectors by their contribution to fault coverage. This assumes that all faults are equally likely. Test engineers can then modify the test program if they discover vectors late in the test program that are efficient in detecting faulty chips. 14.4.5 Fault-Simulation ResultsThe output of a fault simulator separates faults into several fault categories . If we can detect a fault at a location, it is a testable fault . A testable fault must be placed on a controllable net , so that we can change the logic level at that location from '0' to '1' and from '1' to '0' . A testable fault must also be on an observable net , so that we can see the effect of the fault at a PO. This means that uncontrollable nets and unobservable nets result in faults we cannot detect. We call these faults untested faults , untestable faults , or impossible faults . If a PO of the good circuit is the opposite to that of the faulty circuit, we have a detected fault (sometimes called a hard-detected fault or a definitely detected fault ). If the POs of the good circuit and faulty circuit are identical, we have an undetected fault . If a PO of the good circuit is a '1' or a '0' but the corresponding PO of the faulty circuit is an 'X' (unknown, either '0' or '1' ), we have a possibly detected fault ( also called a possible-detected fault , potential fault , or potentially detected fault ). If the PO of the good circuit changes between a '1' and a '0' while the faulty circuit remains at 'X' , then we have a soft-detected fault . Soft-detected faults are a subset of possibly detected faults. Some simulators keep track of these soft-detected faults separately. Soft-detected faults are likely to be detected on a real tester if this sequence occurs often. Most fault simulators allow you to set a fault-drop threshold so that the simulator will remove faults from further consideration after soft-detecting or possibly detecting them a specified number of times. This is called fault dropping (or fault discarding ). The more often a fault is possibly detected, the more likely it is to be detected on a real tester. A redundant fault is a fault that makes no difference to the circuit operation. A combinational circuit with no such faults is irredundant . There are close links between logic-synthesis algorithms and redundancy. Logic-synthesis algorithms can produce combinational logic that is irredundant and 100 % testable for single stuck-at faults by removing redundant logic as part of logic minimization. If a fault causes a circuit to oscillate, it is an oscillatory fault . Oscillation can occur within feedback loops in combinational circuits with zero-delay models. A fault that affects a larger than normal portion of the circuit is a hyperactive fault . Fault simulators have settings to prevent such faults from using excessive amounts of computation time. It is very annoying to run a fault simulation for several days only to discover that the entire time was taken up by simulating a single fault in a RS flip-flop or on the clock net, for example. Figure 14.15 shows some examples of fault categories. 14.4.6 Fault-Simulator Logic SystemsIn addition to the way the fault simulator counts faults in various fault categories, the number of detected faults during fault simulation also depends on the logic system used by the fault simulator. As an example, Cadence’s VeriFault concurrent fault simulator uses a logic system with the six logic values: '0' , '1' , 'Z' , 'L' , 'H' , 'X' . Table 14.8 shows the results of comparing the faulty and the good circuit simulations. From Table 14.8 we can deduce that, in this logic system:
A fault simulator assigns faults to each of the categories we have described. We define the fault coverage as: The number of detectable faults excludes any undetectable fault categories (untestable or redundant faults). Thus, The fault simulator may also produce an analysis of fault grading . This is a graph, histogram, or tabular listing showing the cumulative fault coverage as a function of the number of test vectors. This information is useful to remove dead test cycles , which contain vectors that do not add to fault coverage. If you reinitialize the circuit at regular intervals, you can remove vectors up to an initialization without altering the function of any vectors after the initialization. The list of faults that the simulator inserted is the fault list. In addition to the fault list, a fault dictionary lists the faults with their corresponding primary outputs (the faulty output vector ). The set of input vectors and faulty output vectors that uniquely identify a fault is the fault signature . This information can be useful to test engineers, allowing them to work backward from production test results and pinpoint the cause of a problem if several ASICs fail on the tester for the same reasons.
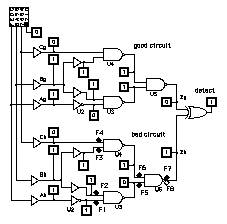
14.4.7 Hardware AccelerationSimulation engines or hardware accelerators use computer architectures that are tuned to fault-simulation algorithms. These special computers allow you to add multiple simulation boards in one chassis. Since each board is essentially a workstation produced in relatively low volume and there are between 2 and 10 boards in one accelerator, these machines are between one and two orders of magnitude more expensive than a workstation. There are two ways to use multiple boards for fault simulation. One method runs good circuits on each board in parallel with the same stimulus and generates faulty circuits concurrently with other boards. The acceleration factor is less than the number of boards because of overhead. This method is usually faster than distributing a good circuit across multiple boards. Some fault simulators allow you to use multiple circuits across multiple machines on a network in distributed fault simulation . 14.4.8 A Fault-Simulation ExampleFigure 14.16 illustrates fault simulation using the circuit of Figure 14.14 . We have used all possible inputs as a test vector set in the following order: {000, 001, 010, 011, 100, 101, 110, 111} . There are eight collapsed SSFs in this circuit, F1–F8. Since the good circuit is irredundant, we have 100 percent fault coverage. The following fault-simulation results were derived from a logic simulator rather than a fault simulator, but are presented in the same format as output from an automated test system. Number of faults in collapsed fault list: 8 Test Vector Faults detected Coverage/% Cumulative/% ----------- --------------- ---------- ------------ FAULT COVERAGE 100.00 % 100.00 % Fault simulation tells us that we need to apply seven test vectors in order to achieve full fault coverage. The highest-quality test vectors are {011} and {100} . For example, test vector {011} detects three faults (F1, F4, and F7) out of eight. This means if we were to reduce the test set to just {011} the fault coverage would be 3/8, or 37 percent. Proceeding in this fashion we reorder the test vectors in terms of their contribution to cumulative test coverage as follows: {011, 100, 010, 111, 000, 001, 101, 110} . This is a hard problem for large numbers of test vectors because of the interdependencies between the faults detected by the different vectors. Repeating the fault simulation gives the following fault grading: Test Vector Faults detected Coverage/% Cumulative/% ----------- --------------- ---------- ------------ Now, instead of using seven test vectors, we need only apply the first four vectors from this set to achieve 100 percent fault coverage, cutting the expensive production test time nearly in half. Reducing the number of test vectors in this fashion is called test-vector compression or test-vector compaction . The fault signatures for faults F1–F8 for the last test sequence, {011, 100, 010, 111, 000, 001, 101, 110} , are as follows: -- ---- ---- -------- -------- The first pattern for each fault indicates which test vectors will fail on the tester (we say a test vector fails when it successfully detects a faulty circuit during a production test). Thus, for fault F1, pattern '10000000' indicates that only the first test vector will fail if fault F1 is present. The second and third patterns for each fault are the POs of the good and bad circuits for each test vector. Since we only have one PO in our simple example, these patterns do not help further distinguish between faults. Notice, that as far as an external view is concerned, faults F1 and F4 have identical fault signatures and are therefore indistinguishable. Faults F1 and F4 are said to be structurally equivalent . In general, we cannot detect structural equivalence by looking at the circuit. If we apply only the first four test vectors, then faults F2 and F3 also have identical fault signatures. Fault signatures are only useful in diagnosing fault locations if we have one, or a very few faults. Not all fault simulators give all the information we have described. Most fault simulators drop hard-detected faults from consideration once they are detected to increase the speed of simulation. With dropped hard-detected faults we cannot independently grade each vector and we cannot construct a fault dictionary. This is the reason we used a logic simulator to generate the preceding results. 14.4.9 Fault Simulation in an ASIC Design FlowAt the beginning of this section we dodged the issue of test-vector generation. It is possible to automatically generate test vectors and test programs (with certain restrictions), and we shall discuss these methods in Section 14.5 . A by-product of some of these automated systems is a measure of fault coverage. However, fault simulation is still used for the following reasons:
[ Chapter start ] [ Previous page ] [ Next page ] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||





 Animation, 3D Art and 3D Models")